Artificial Intelligence of Things (AIoT) is transforming how businesses operate — from predictive maintenance and smart infrastructure to autonomous monitoring and real-time optimization.
Yet many AIoT projects fail to move beyond demos.
The reason is rarely the machine learning model.
In real deployments, AIoT systems succeed or fail based on the quality, observability, and governance of the data pipeline that powers them.
At MetaDesk Global, we’ve seen production accuracy improve without changing a single algorithm — simply by fixing timestamps, data contracts, and feedback loops.
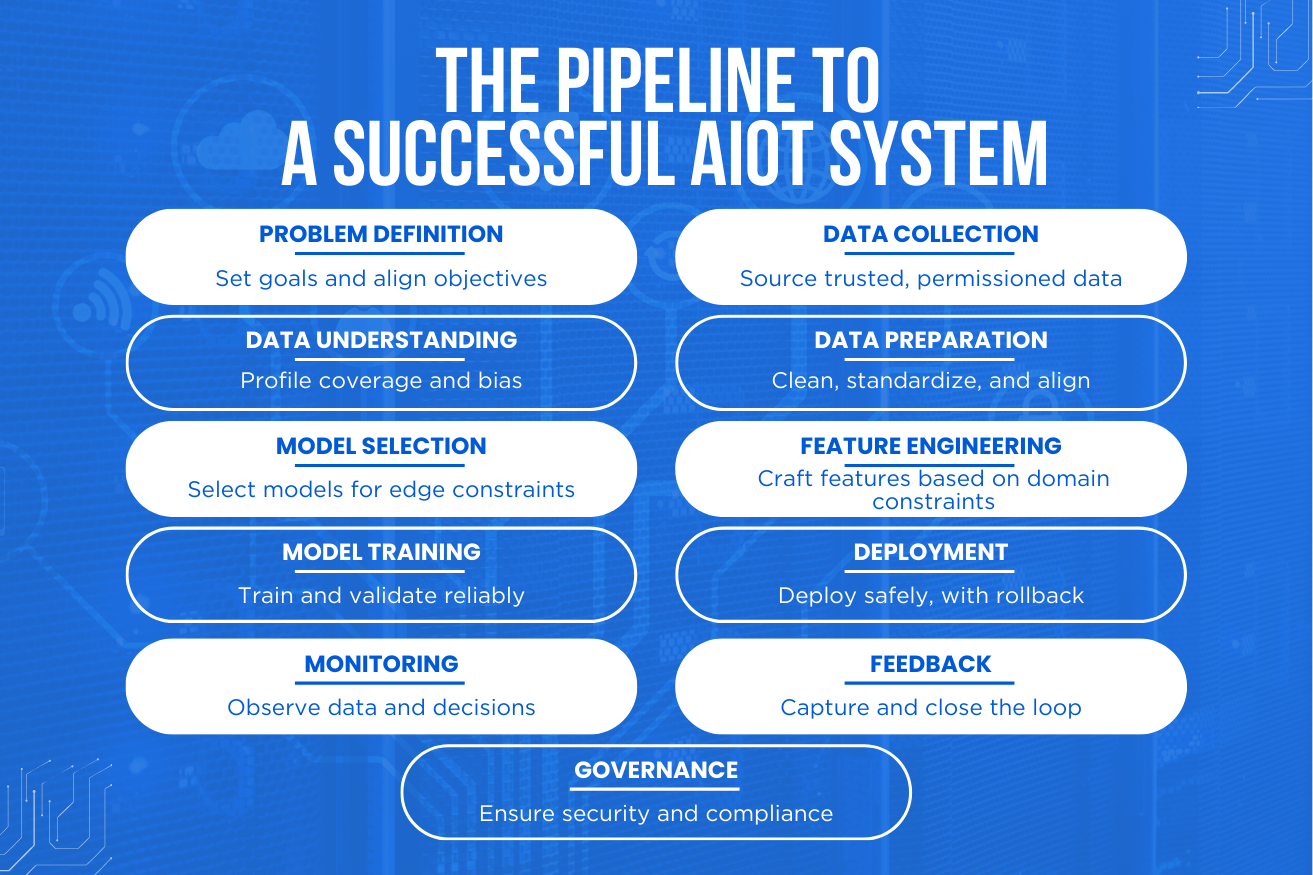
This article explains how modern AIoT pipelines should be designed — from problem definition to long-term governance.
What Is an AIoT Data Pipeline?
An AIoT data pipeline is the complete lifecycle that transforms raw device data into trusted decisions.
It includes:
- Data acquisition from sensors and devices
- Processing at the edge and cloud
- Model execution and inference
- Monitoring, feedback, and governance
Unlike traditional analytics pipelines, AIoT pipelines must operate under:
- Real-time constraints
- Intermittent connectivity
- Limited edge resources
- Long device lifecycles
This makes architecture discipline essential.
Step 1 – Problem Definition Comes First
Every successful AIoT system begins with clarity around the problem.
Before collecting data or training models, teams must define:
- The decision the system should support or automate
- Baseline performance metrics
- Target improvement (accuracy, downtime reduction, cost savings)
- Environmental and regulatory constraints
Without this alignment, AI optimizes the wrong objective.
Step 2 – Reliable and Permissioned Data Collection
AI depends entirely on the quality of its inputs.
Key considerations include:
- Sensor reliability and calibration
- Sampling frequency and synchronization
- Data ownership and consent
- Secure device identity
Untrusted or inconsistent data creates false confidence — not intelligence.
Step 3 – Data Understanding Before Modeling
Before building models, data must be understood.
- Coverage across time and environments
- Seasonality patterns
- Bias detection
- Missing data analysis
Visualizing raw telemetry often reveals system gaps earlier than any model can.
Step 4 – Data Cleaning and Preparation
Production AI requires repeatability.
- Standardized schemas
- Consistent units
- Unified timestamps
- Robust null and outlier handling
Data preparation should be automated and versioned — not handled through one-off notebooks.
Step 5 – Feature Engineering With Edge Constraints
Features translate domain knowledge into machine-readable signals.
In AIoT systems, features must respect:
- Memory limits
- Power budgets
- Latency requirements
Aggregation windows, event encoding, and signal compression must be designed with deployment targets in mind.
Step 6 – Model Selection Based on Reality
The best model is not always the most complex.
- Accuracy
- Interpretability
- Inference latency
- Power consumption
- Maintainability
In many edge deployments, simpler models outperform deep networks due to stability and explainability.
Step 7 – Training With Representative Data
Models must be trained on data that reflects real-world conditions.
- Environmental diversity
- Device-to-device variation
- Class imbalance handling
- Reproducible training pipelines
Training on laboratory data alone leads to fragile field performance.
Step 8 – Evaluation Beyond Accuracy
Accuracy alone is misleading.
AIoT systems should also be evaluated on:
- Precision and recall
- False-positive tolerance
- Calibration stability
- Robustness across environments
These metrics directly affect operator trust.
Step 9 – Safe Deployment and OTA Strategy
Deployment must be controlled and reversible.
- Edge, cloud, or hybrid execution strategies
- Shadow and canary releases
- OTA with rollback support
- Versioned model management
AI systems must be updatable throughout long device lifecycles.
Step 10 – Monitoring and Observability
Once deployed, systems must be continuously observed.
- Data drift
- Feature distribution changes
- Inference latency
- Cost and bandwidth usage
- Decision logs
If you cannot observe why a system acted, you cannot trust it.
Step 11 – Feedback and Continuous Learning
True intelligence comes from closed feedback loops.
- Capturing operator outcomes
- Converting logs into labeled data
- Controlled retraining cycles
- Versioned datasets and models
Logs alone are not learning — feedback is.
Step 12 – Governance, Security, and Compliance
As AIoT systems influence real-world outcomes, governance becomes mandatory.
- Role-based access control (RBAC)
- Audit trails
- Data privacy enforcement
- Explainability and model documentation
- Regulatory readiness
Governance transforms AI from experimentation into trust.
Why Pipelines Matter More Than Models
AI models evolve quickly.
Pipelines do not.
A well-designed pipeline allows:
- Model upgrades without system redesign
- Reliable scaling
- Long-term maintainability
- Safer autonomous operation
The difference between a demo and a dependable AIoT product is not intelligence — it’s infrastructure discipline.
How MetaDesk Global Designs Production-Ready AIoT Systems
At MetaDesk Global, we help organizations move from pilots to scalable AIoT deployments by focusing on:
- End-to-end system architecture
- Edge and cloud pipeline design
- Secure OTA strategies
- Data observability and governance
- Long-term lifecycle engineering
Because in production, boring, repeatable systems outperform clever but fragile ones.
Final Thoughts
AIoT success is not achieved by adding a smarter model.
It is achieved by building:
- Reliable data flows
- Strong feedback loops
- Transparent decision-making
- Governed infrastructure
When the pipeline is strong, intelligence naturally follows.